
Analysis of sentiment in political speeches
Sentiment Analysis of Speeches
Introduction
Sentiment analysis is a natural language processing (NLP) technique that can be used to determine whether of a piece of text has positive, neutral or negative sentiment. In this blog post, we will determine the sentiment of the Annual Messages to Congress on the State of the Union by the Presidents of the United States.
We will train our own sentiment analysis model by fine tuning a pre-trained DistilBERT model on the First GOP Debate Twitter Sentiment dataset.
This time we will use Python with PyTorch, fast.ai, and HugginFace Transformers library. Just to learn and practice with different libraries.
Goal
This will be the result:
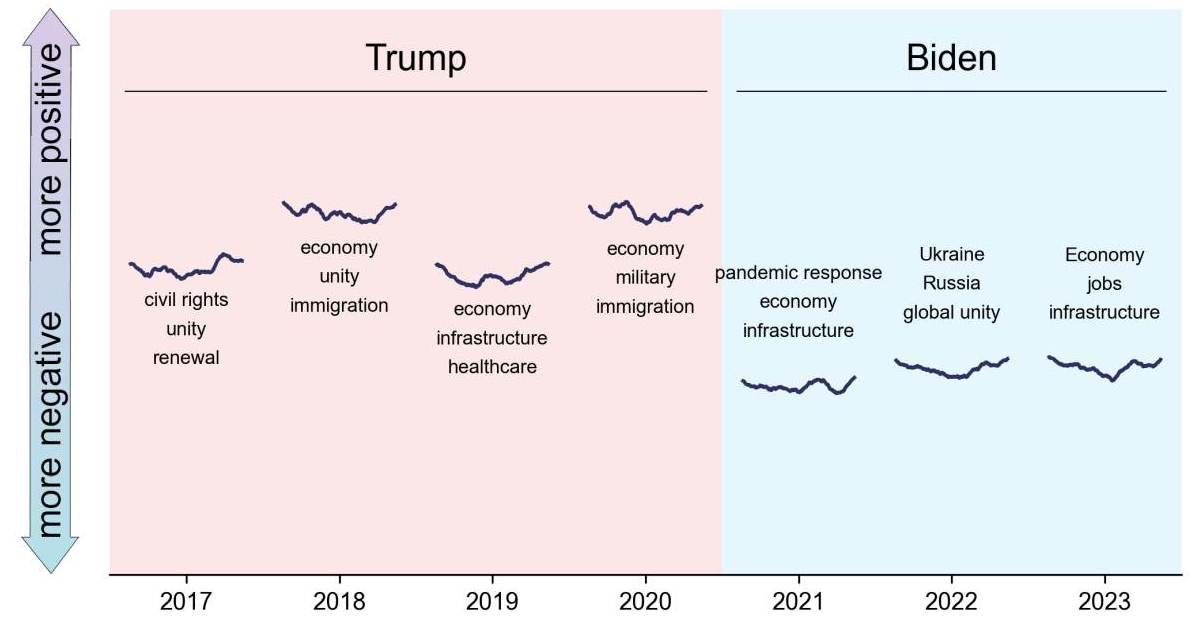
Here the sentiment of each speech is shown as a curve, and the shift of the curves along the y-axis denotes the (exaggerated) average sentiment of the speech.
Let’s get started.
Getting the Data
We can use BeautifulSoup to scrape the speeches from the American Presidency Project website.
It is quite simple and looks something like this:
from bs4 import BeautifulSoup
import requests
url = 'https://www.presidency.ucsb.edu/documents/presidential-documents-archive-guidebook/annual-messages-congress-the-state-the-union'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# find list of terms
rows = soup.select('table tbody tr')
first_row_cells = rows[0].select('td')[2:]
terms = [cell.text for cell in first_row_cells]
… and so on. I will only give code snippets here, because the code is too long to be included in this blog post.
Let’s train the model
We use the HuggingFace Transformers library in combination with PyTorch and fast.ai. We will fine-tune a pre-trained DistilBERT model for our classification task. For this, we use the labeled dataset from a similar domain, i.e., the First GOP Debate Twitter Sentiment dataset.
Some of the code is based on this blog post.
import numpy as np
import pandas as pd
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from fastai.text.all import *
# Load the distilbert tokenizer and model
hf_tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
hf_model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=3,
)
# Create the interface to the HF model
class HF_Dataset(torch.utils.data.Dataset):
def __init__(self, df, hf_tokenizer=hf_tokenizer):
self.df = df
self.hf_tokenizer = hf_tokenizer
def __len__(self):
return len(self.df)
def decode(self, token_ids):
return ' '.join([hf_tokenizer.decode(x) for x in tokenizer_outputs['input_ids']])
def decode_to_original(self, token_ids):
return self.hf_tokenizer.decode(token_ids.squeeze())
def __getitem__(self, index):
row = self.df.iloc[index]
text = row['text']
label = torch.tensor(row.loc[['Negative', 'Positive', 'Neutral']].array)
tokenizer_output = self.hf_tokenizer(text, return_tensors="pt", padding='max_length', truncation=True, max_length=512)
tokenizer_output['input_ids'].squeeze_()
tokenizer_output['attention_mask'].squeeze_()
return tokenizer_output, label
class HF_Model(nn.Module):
def __init__(self, hf_model):
super().__init__()
self.hf_model = hf_model
def forward(self, tokenizer_outputs):
model_output = self.hf_model(**tokenizer_outputs)
return model_output.logits
# train_df and valid_df are the training and validation datasets
# which are created from the twitter sentiment dataset
train_dataset = HF_Dataset(train_df, hf_tokenizer)
valid_dataset = HF_Dataset(valid_df, hf_tokenizer)
train_dl = DataLoader(train_dataset, bs=16, shuffle=True)
valid_dl = DataLoader(valid_dataset, bs=16)
dls = DataLoaders(train_dl, valid_dl)
# we use CUDA and fp16 to speed up the training
model = HF_Model(hf_model)
learn = Learner(dls, model.cuda(), loss_func=nn.CrossEntropyLoss(), metrics=[accuracy_multi])
learn = learn.to_fp16()
Let’s find a good learning rate:
learn.lr_find()
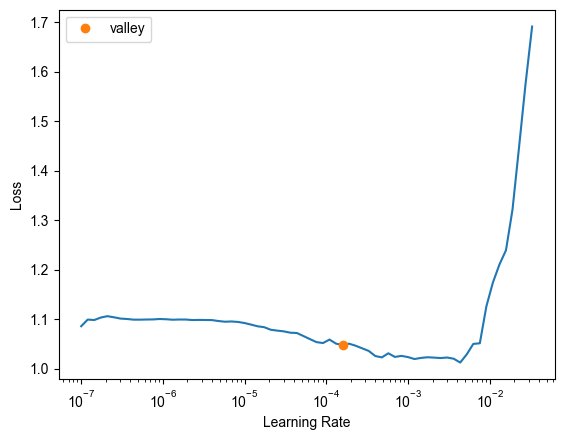
And fine-tune the model:
learn.fit_one_cycle(3, 2e-5)
This should give an accuracy of around 0.8. Not perfect, but good enough to keep going. Of course you should check some of the predictions to see if the model is doing a good job.
Analyzing the Speeches
We will now use our fine-tuned model to analyze the sentiment of the presidential speeches to congress. First, we will split them into sentences (splitting into paragraphs also works). Then we can use the predict method of the Learner object to get the sentiment of each piece of text.
import spacy
# create a list of sentences
# we use spacy because it is smarter than just splitting by '.'
nlp = spacy.load('en_core_web_sm')
speech_ids = []
for text in texts:
doc = nlp(text)
s = [sent.text.strip() for sent in doc.sents if len(sent.text.strip()) > 1]
sentences.extend(s)
# get the predictions from our model
dl_sentences = DataLoader(HF_Dataset(sentences), bs=16)
preds, _targets = learn.get_preds(dl=dl_sentences, reorder=False)
probs = torch.softmax(preds, dim=1)
There is quite a bit of pandas dataframe wrangling to get the data into the right format, but I will skip this here.
Bonus: Most Important Topics
We have the sentiments, but we can go one step further. We can use a Large Language Model (LLM) to get the most important topics of the speeches. An easy way to do this is to install LM Studio, download one of the open-source LLMs (I used a Mistral 7B model), start a local server, and then access it via the OpenAI API:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:1234/v1", api_key="not-needed")
completion = client.chat.completions.create(
model="local-model",
messages=[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What are the three most important topics in the following political speech." + text}])
response = completion.choices[0].message.content
You can play around more with the prompts and the model to get better results. For instance, I used a longer prompt that also contained a few examples of the desired output.
Based on this code, we can automatically create a plot containing the sentiment as well as the most important topics of the speeches from the last 40 years:

This is a large image, so you can open it in a new tab to see it in full size.
Here the shift along the y-axis denotes the average sentiment of the speech. And the little curves show the (smoothed) sentiment in the course of the speech. You can see that most speeches follow a feedback sandwich pattern, with a positive start and a positive end. Also, there are significant differences between the speeches of different presidents.
Conclusion and caveats
OK, so the code produces results. But what do they mean? It is clear that the sentiment analysis model is not perfect, and the LLM is not perfect either.
It is very important to dig deeper into the data and the model outputs. For instance, we can see that simple positive sentences have the highest probability of being classified as positive, for instance in Donald Trump’s speech:
- Great job.
- [Applause] Great job.
- Preston, a job well done.
- [Applause] I think they like you, Steve.
- And I like that answer.
Also, we should probably have removed any text in square brackets, because it is often applause or other non-speech text.
Sentences that address important challenges of the country are often classified as negative. For instance in Joe Biden’s speech:
- We've all seen the knee of injustice on the neck of Black Americans.
- If you've watched any of it—and you were all busy; I'm sure you didn't have much time—that's what virtually every nation said, even the ones that aren't doing their fair share.
- And you can see on television the viciousness of the hate crimes we've seen over the past year—this past year and for too long.
- Two million women have dropped out of the workforce during this pandemic—2 million, and too often because they couldn't get the care they needed to care for their child or care for an elderly parent who needs help.
- They believe we're too full of anger and division and rage.
So that puts the simple plots into perspective. Nevertheless, we can get a quick overview of the speeches, their sentiments, and the most important topics with this code.
Also, it was educational and a lot of fun to play around with NLP and LLMs.
Disclaimer
I have to say that I am not a political scientist, and I do not want to make any political statements with this post. So I will not dive deeper into the interpretation of the results. I just wanted to show how to use NLP and LLMs to analyze text. I hope you enjoyed this post. If you have any questions or comments, please let me know.
Postscript: Julia vs. Python
I made the deliberate choice to use Python, PyTorch and fast.ai. It is always nice to code in Python again. However, I still prefer Julia for most of my work. It is faster, it is smoother, and the package management is sooo much better. But Python has sentimental value for me. Pun intended.